使用 Spatial Pyramid Pooling 让 CNN 接受可变尺寸的图像
在传统 CNN 中,由于 Fully-Connected 层的存在,输入图像的尺寸受到了严格限制。通常情况下,我们需要对原始图片进行裁剪(crop)或变形(warp)的操作来调整其尺寸使其适配于 CNN。然而裁剪过的图片可能包含不了所需的所有信息,而改变纵横比的变形操作也可能会使关键部分产生非期望的形变。由于图片内容的丢失或失真,模型的准确度会受到很大的影响。


目录
参考论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
传统 CNN 的弊端
在传统 CNN 中,由于 Fully-Connected 层的存在,输入图像的尺寸受到了严格限制。通常情况下,我们需要对原始图片进行**裁剪(crop)或变形(warp)**的操作来调整其尺寸使其适配于 CNN。然而裁剪过的图片可能包含不了所需的所有信息,而改变纵横比的变形操作也可能会使关键部分产生非期望的形变。由于图片内容的丢失或失真,模型的准确度会受到很大的影响。

上图中分别表现了两种 resize 的方法:裁剪(左)、变形(右)。它们对原图都造成了非期望的影响。
SPP-Net 概述
从 CNN 的结构来看,我们需要让图像在进入 FC 层前就将尺度固定到指定大小。通过修改卷积层或池化层参数可以改变图片大小,其中池化层不具有学习功能,其参数不会随着训练过程变化,自然而然承担起改变 spatial size 的工作。我们在第一个 FC 层前加入一个特殊的池化层,其参数是随着输入大小而成比例变化的。

图1. 使用 crop 或 warp 方法的 CNN 的层级结构。图2. 在卷积层与第一个全连接层之间加入 SPP 层。
SPP-Net 中有若干个并行的池化层,将卷积层的结果 \([w\times h\times d]\) 池化成 \([1\times 1],[2\times 2], [4\times 4], \cdots\) 的一层层结果,再将其所有结果与 FC 层相连。
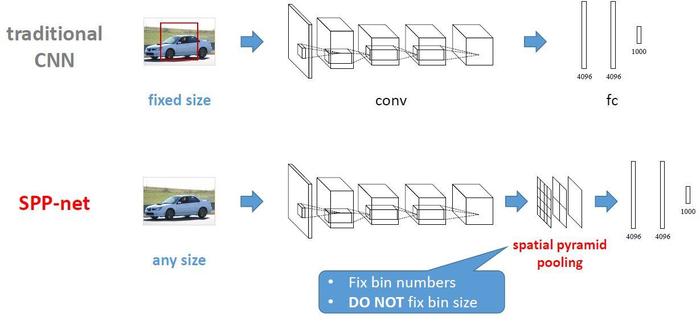
当输入为任意大小的图片时,我们可以随意进行卷积、池化,在 FC 层之前,通过 SPP 层,将图片抽象出固定大小的特征(即多尺度特征下的固定特征向量抽取)。
SPP-Net 结构细节
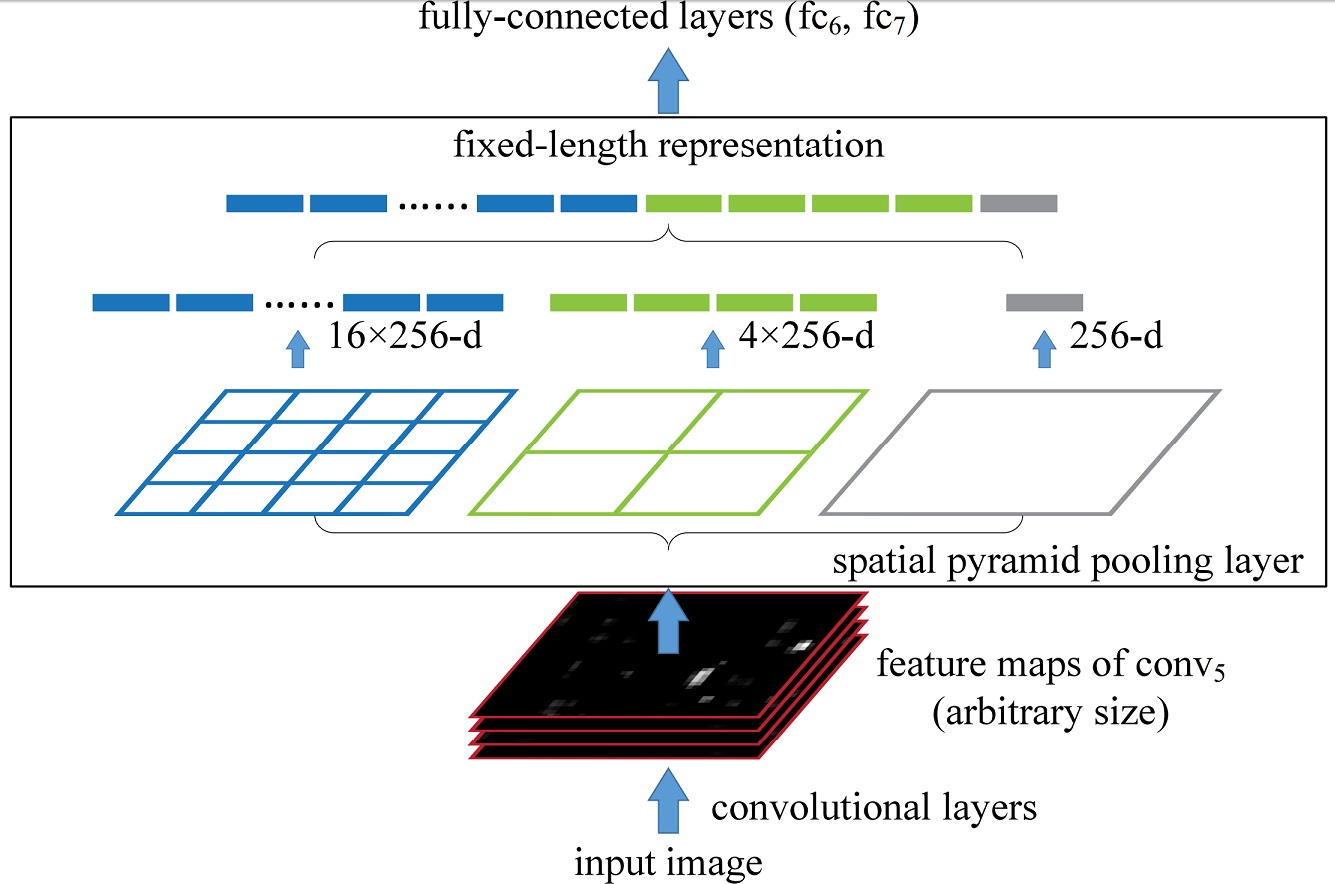
结构如上所示,已知输入 conv5 的大小是 \([w\times h\times d]\),SPP 中某一层输出结果大小为 \([n\times n\times d]\),那么如何设定该层的参数呢?
- 感受野大小 \([w_r\times h_r]\):\(w_r = \lceil\frac{w}{n}\rceil\),\(h_r = \lceil\frac{h}{n}\rceil\)
- 步长 \((s_w, s_h)\):\(s_w = \lfloor\frac{w}{n}\rfloor\),\(s_h = \lfloor\frac{h}{n}\rfloor\)
假设输入是 \([30\times 42\times 256]\),对于 SPP 中 \([4\times 4]\) 的层而言,其:
- 感受野大小应为 \([\lceil\frac{30}{4}\rceil\times \lceil\frac{42}{4}\rceil] = [8\times 11]\)
- 步长应为 \((\lfloor\frac{30}{4}\rfloor, \lfloor\frac{42}{4}\rfloor) = (7, 10)\)
最后再将 SPP 中所有层的池化结果(池化操作通常是取感受野内的 max)变成 1 维向量,并与 FC 层中的神经元连接。
如上图中的 SPP 有三层(\([1\times 1],[2\times 2],[4\times 4]\)),则通过 SPP 后的特征有 \( (1+4+16)\times 256\) 个。
SPP-Net 训练方法
虽然使用了 SPP,理论上可以直接用变尺度的图像集作为输入进行训练,但是常用的一些框架(如 CUDA-convnet、Caffe等)在底层实现中更适合固定尺寸的计算(效率更高)。原论文中提及了两种训练方法:
- Single-Size:将所有的图片固定到同一尺度。
- Multi-Size:将原图片通过 crop 得到某一尺度 A,再把 A 通过 warp 放缩成更小的尺寸 B。之后用 A 尺度训练一个 epoch,再用 B 尺度训练一个 epoch,交替迭代。
由何凯明等人的实验结果可以发现,采用 Multi-Size 方法训练得到的模型错误率更低,且收敛速度更快。
在 pytorch 框架中实现 SPP
class SpatialPyramidPool2D(nn.Module):
"""
Args:
out_side (tuple): Length of side in the pooling results of each pyramid layer.
Inputs:
- `input`: the input Tensor to invert ([batch, channel, width, height])
"""
def __init__(self, out_side):
super(SpatialPyramidPool2D, self).__init__()
self.out_side = out_side
def forward(self, x):
out = None
for n in self.out_side:
w_r, h_r = map(lambda s: math.ceil(s/n), x.size()[2:]) # Receptive Field Size
s_w, s_h = map(lambda s: math.floor(s/n), x.size()[2:]) # Stride
max_pool = nn.MaxPool2d(kernel_size=(w_r, h_r), stride=(s_w, s_h))
y = max_pool(x)
if out is None:
out = y.view(y.size()[0], -1)
else:
out = torch.cat((out, y.view(y.size()[0], -1)), 1)
return out可以在模型中插入该模块,如:
nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(),
SpatialPyramidPool2D(out_side=(1,2,4))
)