Dropout - 解决神经网络模型过拟合问题的大杀器
之前训练了一些深度神经网络模型,几乎都会遇到过拟合的问题,调整过学习率也调整过隐层的层级和数量,但效果依然不尽人意。直到魔改别人代码的时候才发现有个 Dropout,今天来做个小总结。


导言
之前训练了一些深度神经网络模型,几乎都会遇到过拟合的问题,调整过学习率也调整过隐层的层级和数量,但效果依然不尽人意。直到魔改别人代码的时候才发现有个 Dropout,从测试结果来看,它的确不失为一种有效且简单的办法。今天来做个小总结。
Dropout 是怎样工作的?
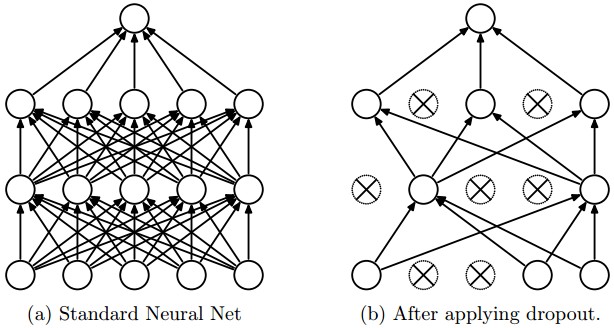
先来看张图,图(a)是标准的神经网络,所有的神经元都会对最终的输出作出贡献。而图(b)中部分神经元被打上了×,我们称它被 舍弃(dropout) 了。我们设置 Dropout 率为 \(p\),当一个神经元以概率 \(p\) 被舍弃后,它的输出为 0。也就是说在训练过程中,该神经元不会对 forward 和 backward 作出任何贡献。
对于某个隐层神经元,我们把它的激活函数由 \(f(h)\) 变成 \(g(h) = f(h)\odot D\),其中 \(D\) 是一个与 \(f(h)\) 等维的 Bernoulli 向量(参数为 \(p\))。
工作流程
- 在隐层神经元中以概率 \(p\) 随机选择若干个神经元进行舍弃,输入输出神经元不能舍弃。
- 将一组 batch 的输入 \(\boldsymbol{x}\) 通过剩余网络进行 BP 训练,更新剩余网络的参数。
- 重复上述流程。
为什么 Dropout 能这样工作?
从流程来看,应用了 Dropout 的神经网络好像进行了很玄学的训练方式,为什么这样就能解决过拟合呢?
我这里不做抽象的数学理论分析,直观上来看有以下几个方面促成了它的功能:
- 取平均:由于隐层神经元的随机抽取,每次训练的网络结构都不同,但这些不同的网络又共享着部分隐层神经元的权重,这些网络可能会产生不同程度的过拟合,但是将它们取平均之后,一些过拟合会抵消,这便达成了整体上网络的过拟合程度的减少。
- 减少共适应性:我们希望网络在做预测的时候不应该对一些特征片段太过敏感,就算是缺少某些特征,这个网络也应该从其他的特征中学习出一些有用的信息。隐层神经元随机抽取后,由于结构每次都不同,某些本来是有固定关系的隐节点之间的关系被拆散,这样一来,参数的更新就不会依赖这些固定关系,这就避免了某些特征只在其他一些特征下才有效的情况。